
Python 多进程、协程异步抓取英雄联盟皮肤并保存在本地
时间:2021-11-09 13:51:16
手机看文章
扫描二维码
随时随地手机看文章
[导读]作者|俊欣来源 |关于数据分析与可视化就在11月7日晚间,《英雄联盟》S11赛季全球总决赛决斗,在冰岛拉开“帷幕”,同时面向全球直播。在经过了5个小时的鏖战,EDG战队最终以3:2战胜来自韩国LCK赛区的DK战队,获得俱乐部队史上首座全球总决赛冠军。夺冠的消息瞬间引爆全网,包括小...
 夺冠的消息瞬间引爆全网,包括小编的朋友圈也被刷屏了,今天小编就写一篇与之相关的文章,通过单线程、多进程以及异步协程等方法来抓取英雄联盟的皮肤并下载。
夺冠的消息瞬间引爆全网,包括小编的朋友圈也被刷屏了,今天小编就写一篇与之相关的文章,通过单线程、多进程以及异步协程等方法来抓取英雄联盟的皮肤并下载。
传统数据抓取 VS 高性能数据抓取
传统的数据抓取都是运行在单线程上的,先用获取到目标页面中最大的页数,然后循环抓取每个单页数据并进行解析,按照这样的思路,会有大量的时间都浪费在等待请求传回的数据上面,如果在等待第一个页面返回的数据时去请求第二个页面,就能有效地提高效率,下面我们就通过单线程、多进程以及异步协程的方式分别来简单的实践一下。页面分析
目标网站:https://lol.qq.com/data/info-heros.shtml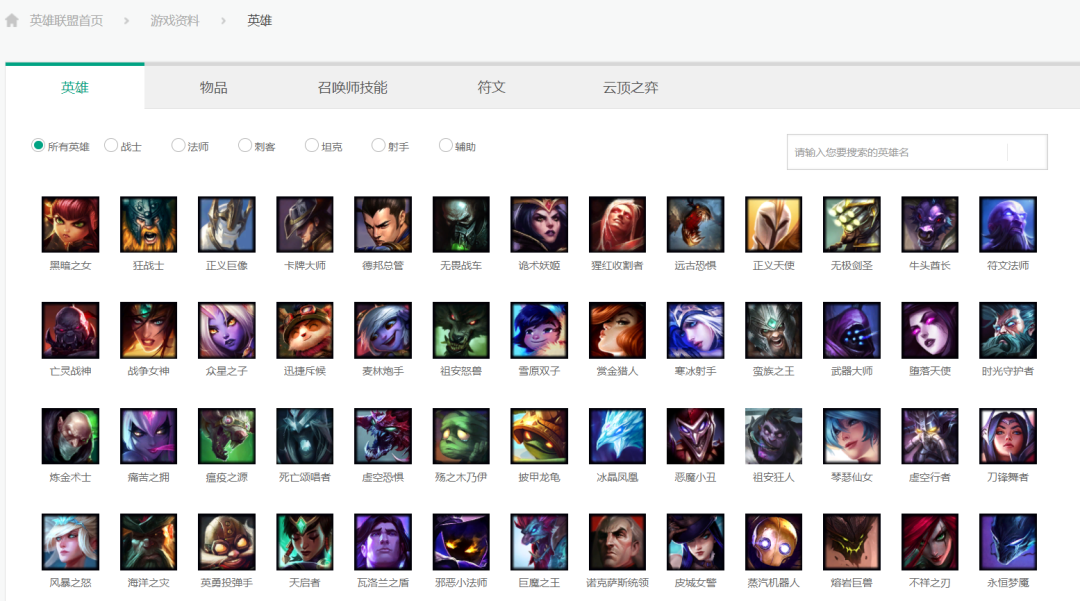 官网的界面如图所示,上面的每一张小图代表每一个英雄,我们知道每一个英雄有多个皮肤,我们的目标就是爬取每一个英雄的所有皮肤,并且保存在本地;打开一个英雄显示他所有的皮肤,如下图所示,
官网的界面如图所示,上面的每一张小图代表每一个英雄,我们知道每一个英雄有多个皮肤,我们的目标就是爬取每一个英雄的所有皮肤,并且保存在本地;打开一个英雄显示他所有的皮肤,如下图所示,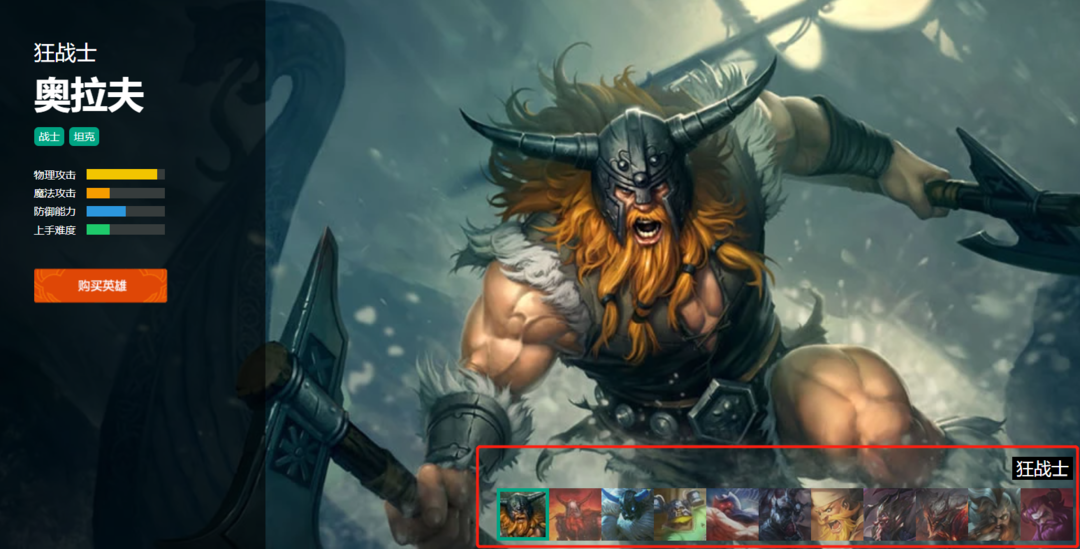 我们打开浏览器里面的开发者工具,查看皮肤数据的接口,
我们打开浏览器里面的开发者工具,查看皮肤数据的接口,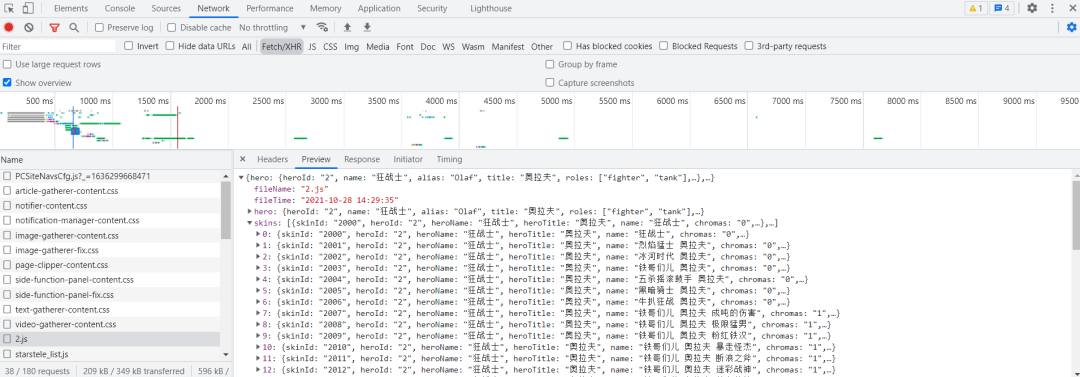 可以看到皮肤的信息是通过
可以看到皮肤的信息是通过json的数据格式来进行传输的,并且存放皮肤的url也是有一定规律的,和英雄的ID相挂钩url1 = 'https://game.gtimg.cn/images/lol/act/img/js/hero/1.js'
url2 = 'https://game.gtimg.cn/images/lol/act/img/js/hero/2.js'
url3 = 'https://game.gtimg.cn/images/lol/act/img/js/hero/3.js'
url4 = 'https://game.gtimg.cn/images/lol/act/img/js/hero/4.js'
因此我们也可以自己来构造这个url格式'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'.format(i)
单线程方案
我们先来看一下单线程的方案def get_page():
page_urls = []
for i in range(1, 10):
url = 'https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js'.format(i)
page_urls.append(url)
return page_urls
# 获取各英雄皮肤的链接
def get_img_urls():
results_list = []
page_urls = get_page()
for page_url in page_urls:
res = requests.get(page_url, headers=headers)
result = res.content.decode('utf-8')
result_dict = json.loads(result)
skins_list = result_dict["skins"]
for skin in skins_list:
hero_dict = {}
hero_dict['name'] = skin["heroName"]
hero_dict['skin_name'] = skin["name"]
if skin["mainImg"] == '':
continue
hero_dict['imgUrl'] = skin["mainImg"]
results_list.append(hero_dict)
time.sleep(2)
return results_list
# 将各种皮肤保存到本地
def save_image(index, img_url):
path = "skin/" img_url["name"]
if not os.path.exists(path):
os.makedirs(path)
response = requests.get(img_url['imgUrl'], headers = headers).content
with open('./skin/' img_url['name'] '/' img_url['skin_name'] str(index) '.jpg', 'wb') as f:
f.write(response)
上面的代码分别代表的获取各英雄每个皮肤的链接,然后再将各英雄的皮肤图片保存到本地,通过一个主函数将上面的步骤都串联到一起def main():
img_urls = get_img_urls()
print("总共有{}个网页".format(len(img_urls)))
for index, img_url in enumerate(img_urls):
print("目前正处于第{}个".format(img_urls.index(img_url)))
save_image(index, img_url)
print("Done")
爬取这几个网页然后保存到本地的时间总共是需要43秒的时间,接下来我们来看一下多进程的爬取所需要的时间。
多进程的抓取方案
首先来简单的介绍一下进程,进程是系统进行资源分配和调度的最小单位,每一个进程都有自己独立的地址空间,不同进程之间的内存空间不共享,进程与进程之间的通信是由操作系统来传递的,因此通讯效率低,切换开销大。这里我们简单的用多进程来抓取一下各个英雄的皮肤def main():
img_urls = get_img_urls()
print("总共有{}个网页".format(len(img_urls)))
pools = multiprocessing.Pool(len(img_urls))
for index_1, img_url in enumerate(img_urls):
print("目前正处于第{}个".format(img_urls.index(img_url)))
pools.apply_async(save_image, args=(index_1, img_url, ))
pools.close() # 关闭进程池(pool),使其不在接受新的任务。
pools.join() # 主进程阻塞等待子进程的退出, join方法要在close或terminate之后使用
print("Done")
整体下来需要的时间是29秒,比上面的单线程要快出许多。
异步协程的抓取方案
与异步相对立的则是同步,顾名思义,同步具体指的各个任务并不是独立进行的,而是按照顺序交替进行下去的,在一个任务进行完之后得到结果才进行下一个的任务。而异步则是各个任务可以独立的运行,一个任务的运行不受另外一个任务的影响。而这里提到的协程,英文叫做Coroutine,也称为是微线程,是一种用户态的轻量级线程,拥有自己的寄存器上下文和栈,在进行调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候恢复先前保存的寄存器上下文和栈。 我们可以利用协程来实现异步操作,比如在发出请求的时候,需要等一段时间才能得到返回的结果,但其实这个等待的时候程序完全可以干其他许多的事情,在响应返回之后再切换回来继续处理,这样可以充分利用 CPU 和其他资源。我们这里用协程来抓取一下各个英雄的皮肤async def save_image(index, img_url):
我们可以利用协程来实现异步操作,比如在发出请求的时候,需要等一段时间才能得到返回的结果,但其实这个等待的时候程序完全可以干其他许多的事情,在响应返回之后再切换回来继续处理,这样可以充分利用 CPU 和其他资源。我们这里用协程来抓取一下各个英雄的皮肤async def save_image(index, img_url):
path = "skin/" img_url["name"]
if not os.path.exists(path):
os.makedirs(path)
response = requests.get(img_url['imgUrl'], headers = headers).content
with open('./skin/' img_url['name'] '/' img_url['skin_name'] str(index) '.jpg', 'wb') as f:
f.write(response)
def main():
loop = asyncio.get_event_loop()
img_urls = get_img_urls()
print("总共有{}个网页".format(len(img_urls)))
tasks_list = [save_image(index, img_url) for index, img_url in enumerate(img_urls)]
try:
loop.run_until_complete(asyncio.wait(tasks_list))
finally:
loop.close()
print("Done")
一整个跑下来,大概是需要33秒的时间,也是比单线程的43秒要快出很多以上便是用单线程、多进程以及异步协程的方式来优化爬虫脚本的性能,感兴趣的读者可以自己照着上面的教程与步骤自己去敲一遍代码,感谢阅读。





