
利用 OpenCV ConvNets 检测几何图形
时间:2021-11-11 13:48:29
手机看文章
扫描二维码
随时随地手机看文章
[导读]作者|小白来源 | 小白学视觉导读人工智能领域中增长最快的子领域之一是自然语言处理(NLP),它处理计算机与人类(自然)语言之间的交互,特别是如何编程计算机以处理和理解大量自然语言数据。自然语言处理通常涉及语音识别、自然语言理解和自然语言生成等。其中,命名实体识别(NER)等信息...
作者 | 小白
来源 | 小白学视觉


if len(image_arr) > 0:
for index,original_image in enumerate(image_arr):
#to store extracted images extracted_quad = [] image = original_image.copy()
#grayscale only if its not already if len(image.shape) > 2: gray = cv2.cvtColor(image.copy(), cv2.COLOR_BGR2GRAY) else: gray = image.copy()
#image preprocessing for quadrilaterals img_dilate = self.do_quad_imageprocessing(gray,self.blocksize,self.thresh_const,self.kernelsize)
if len(img_dilate) > 0:
try: #detect contours cnts = cv2.findContours(img_dilate.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE) cnts = imutils.grab_contours(cnts)
#loop through detected contours for c in cnts: peri = cv2.arcLength(c, True) approx = cv2.approxPolyDP(c, (self.epsilon)* peri, True)
#bounding rec cordinates (x, y, w, h) = cv2.boundingRect(approx)
#get the aspect ratio aspectratio = float(w/h) area = cv2.contourArea(c) if area < self.rec_max_area and area > self.rec_min_area and (aspectratio >= self.aspect_ratio[0] and aspectratio <= self.aspect_ratio[1]):
#check if there are 4 corners in the polygon if len(approx) == 4: cv2.drawContours(original_image,[c], 0, (0,255,0), 2) roi = original_image[y:y h, x:x w] extracted_quad.append(roi)
except Exception as e: print('The following exception occured during quad shape detection: ',e)
self.extracted_img_data.append([original_image,extracted_quad,name_arr[index]])
else: print('No image is found during the extraction process')
images = []
#get the pdf file for x in os.listdir(dirname): if (dirname.split('.')[1]) == 'pdf': pdf_filename = x images_from_path = convert_from_path(os.path.join(dirname),dpi=300, poppler_path = r'C:\Program Files (x86)\poppler-0.68.0_x86\poppler-0.68.0\bin')for image in images_from_path: images.append(np.array(image))
return images
Y_test_orig = to_categorical(Y_test_orig, num_classes=2) Y_train_orig = to_categorical(Y_train_orig, num_classes=2)
# 3 layer ConvNetmodel = models.Sequential()model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(32,32,1)))model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))model.add(layers.MaxPooling2D((2, 2)))
#dense layermodel.add(layers.Flatten())
#add the regulizermodel.add(layers.Dense(128, activation='linear', activity_regularizer=l2(0.0003)))model.add(layers.Dense(128, activation='relu'))model.add(layers.Dense(2, activation='sigmoid'))
model.summary()
from keras.optimizers import Adamopt = Adam(lr=0.001)model.compile(optimizer=opt, loss=keras.losses.categorical_crossentropy, metrics=['accuracy'])
ntrain = len(X_train_orig)nval = len(X_test_orig)X_train_orig = X_train_orig.reshape((len(X_train_orig),32,32,1)) X_test_orig = X_test_orig.reshape((len(X_test_orig),32,32,1))
train_datagen = ImageDataGenerator(rescale = 1./255,rotation_range = 40, width_shift_range = .2, height_shift_range = .2, shear_range = .2, zoom_range = .2, horizontal_flip = True)
val_datagen = ImageDataGenerator(rescale = 1./255)
train_generator = train_datagen.flow(X_train_orig,Y_train_orig,batch_size=32)val_generator = val_datagen.flow(X_test_orig,Y_test_orig,batch_size = 32)
#X_train_orig, X_test_orig, Y_train_orig,Y_test_orighistory = model.fit_generator(train_generator,steps_per_epoch = ntrain/32, epochs = 64, validation_data = val_generator, validation_steps = nval/32 )
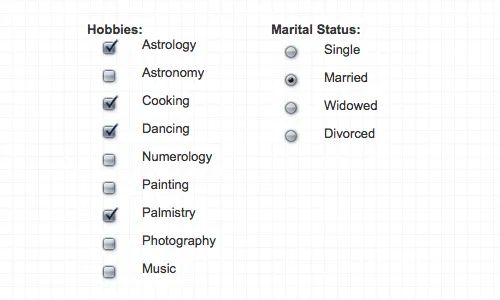
第3步中,我们将把所有内容整合在一个Sklearn pipeline中,并通过predict函数将其公开。我们没有介绍的一个重要功能是将复选框或单选按钮与文档中相应的文本相关联。在实际应用中,仅仅检测没有关联的元素是毫无用处的。
来源 | 小白学视觉
if len(image_arr) > 0:
for index,original_image in enumerate(image_arr):
#to store extracted images extracted_quad = [] image = original_image.copy()
#grayscale only if its not already if len(image.shape) > 2: gray = cv2.cvtColor(image.copy(), cv2.COLOR_BGR2GRAY) else: gray = image.copy()
#image preprocessing for quadrilaterals img_dilate = self.do_quad_imageprocessing(gray,self.blocksize,self.thresh_const,self.kernelsize)
if len(img_dilate) > 0:
try: #detect contours cnts = cv2.findContours(img_dilate.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE) cnts = imutils.grab_contours(cnts)
#loop through detected contours for c in cnts: peri = cv2.arcLength(c, True) approx = cv2.approxPolyDP(c, (self.epsilon)* peri, True)
#bounding rec cordinates (x, y, w, h) = cv2.boundingRect(approx)
#get the aspect ratio aspectratio = float(w/h) area = cv2.contourArea(c) if area < self.rec_max_area and area > self.rec_min_area and (aspectratio >= self.aspect_ratio[0] and aspectratio <= self.aspect_ratio[1]):
#check if there are 4 corners in the polygon if len(approx) == 4: cv2.drawContours(original_image,[c], 0, (0,255,0), 2) roi = original_image[y:y h, x:x w] extracted_quad.append(roi)
except Exception as e: print('The following exception occured during quad shape detection: ',e)
self.extracted_img_data.append([original_image,extracted_quad,name_arr[index]])
else: print('No image is found during the extraction process')
images = []
#get the pdf file for x in os.listdir(dirname): if (dirname.split('.')[1]) == 'pdf': pdf_filename = x images_from_path = convert_from_path(os.path.join(dirname),dpi=300, poppler_path = r'C:\Program Files (x86)\poppler-0.68.0_x86\poppler-0.68.0\bin')for image in images_from_path: images.append(np.array(image))
return images
-
勾选复选框
-
空复选框
-
其他
Y_test_orig = to_categorical(Y_test_orig, num_classes=2) Y_train_orig = to_categorical(Y_train_orig, num_classes=2)
# 3 layer ConvNetmodel = models.Sequential()model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(32,32,1)))model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))model.add(layers.MaxPooling2D((2, 2)))
#dense layermodel.add(layers.Flatten())
#add the regulizermodel.add(layers.Dense(128, activation='linear', activity_regularizer=l2(0.0003)))model.add(layers.Dense(128, activation='relu'))model.add(layers.Dense(2, activation='sigmoid'))
model.summary()
from keras.optimizers import Adamopt = Adam(lr=0.001)model.compile(optimizer=opt, loss=keras.losses.categorical_crossentropy, metrics=['accuracy'])
ntrain = len(X_train_orig)nval = len(X_test_orig)X_train_orig = X_train_orig.reshape((len(X_train_orig),32,32,1)) X_test_orig = X_test_orig.reshape((len(X_test_orig),32,32,1))
train_datagen = ImageDataGenerator(rescale = 1./255,rotation_range = 40, width_shift_range = .2, height_shift_range = .2, shear_range = .2, zoom_range = .2, horizontal_flip = True)
val_datagen = ImageDataGenerator(rescale = 1./255)
train_generator = train_datagen.flow(X_train_orig,Y_train_orig,batch_size=32)val_generator = val_datagen.flow(X_test_orig,Y_test_orig,batch_size = 32)
#X_train_orig, X_test_orig, Y_train_orig,Y_test_orighistory = model.fit_generator(train_generator,steps_per_epoch = ntrain/32, epochs = 64, validation_data = val_generator, validation_steps = nval/32 )
第3步中,我们将把所有内容整合在一个Sklearn pipeline中,并通过predict函数将其公开。我们没有介绍的一个重要功能是将复选框或单选按钮与文档中相应的文本相关联。在实际应用中,仅仅检测没有关联的元素是毫无用处的。





