网站:21ic.com
多次自我突破的摩尔定律,几番“压榨”下,虽说有望回归两年一更新的频率,但还是有很多人感叹“廉颇老矣”。不过事实上,摩尔定律在提出之时,就在论文的第二页指明了摩尔定律失效的前路,这就是电子行业所追捧的“异构计算”,intel现称之为XPU(CPU+GPU+FPGA+加速器)。
材料受到了限制,所以才有了电化学镀铜和机械平面化的双镶嵌结构;物理受到了限制,所以才有了金属栅极和高K电介质;制程受到了限制,神说“要有光”,所以才有了光刻技术……回溯1965年,intel的创始人戈登·摩尔提出了改变世界的
摩尔定律至今已经自我突破了三次瓶颈。
虽然几经放缓,
intel已让其重新回归两年一更新。
但实际上,我们仍然不知道1nm节点后的名字,这一迷之领域仍是纸上谈兵的阶段。反观登纳德缩放比例定律和阿姆达尔定律也基本进入瓶颈期,
现在正是异构计算,即加速计算的时代。
今年4月,intel提出
XPU+oneAPI的超异构计算
的概念,即通过CPU、GPU、FPGA和其他加速器的混合式架构,配合统一开发平台oneAPI进行软硬的有机结合方式进行超级加速计算。同期,全新的计算架构Xe被一并提出,并在今年8月正式宣布Xe图形架构下的几款独立显卡。
时至今日,大势已至,intel正式“亮刃”,拔剑反复打磨的“干将和莫邪”,尽数展示了intel一直遵循戈登·摩尔论文的成果。
11月11日,intel召开“XPU和软件发布会”,发布了独立服务器GPU,并宣布将于今年12月正式交付oneAPI Gold版本,21ic中国电子网记者受邀参加此次发布会。

手游作为可以随手畅玩的一种极佳消遣方式,逐渐成为现代人放松的好方法。任何技术参数都是口说无凭,直接看intel发布的这款服务器GPU到底有什么神奇之处。
根据intel的介绍,新华三
(H3C)
XG310是一款云服务GPU,在相比传统卡3/4的长度
(全高x16 PCle 3.0)
下,封装了4颗intel服务器GPU。
典型双卡系统之中,可支持120个Android游戏并发用户,而这一数字最高甚至可以扩展到160个并发用户,实际数量取决于具体游戏和服务器配置。
值得一提的是,在使用至强(Xeon)可扩展处理器下,即使不扩展服务器数量,可直接扩展显卡容量,在每个系统上支持更多流和订阅用户,并且同时实现较低的总体拥有成本(TCO)。
换言之,只需要两张GPU,无需再单独购置服务器,就多能满足120个玩家实时连线游戏的任务。
数据显示,2017至2022年视频直播将增加15倍、游戏流量将增加9倍,到2022年视频将占全球IP流量的82%,而Android占据了全球移动设备的74%,intel正是看重了这一重大转变因此首次发布了其数据中心独立图形显卡intel Server GPU。
这是一款基于
Xe-LP微架构的高密度、低延时独立GPU,
而本款产品的特殊之处在于除了瞄准了视频和游戏渲染应用场景下的数据中心,更加
优化了对Linux操作系统的支持,
使得不同操作系统之间代码复用成为了可能,也使得这款独立GPU注定能够成为Android游戏云服务的新宠。
参数上,intel Server GPU配备
128-bit渲染管线
(128-bit wide pipeline)
和
8GB LPDDR4 专用板载低功耗显存
。
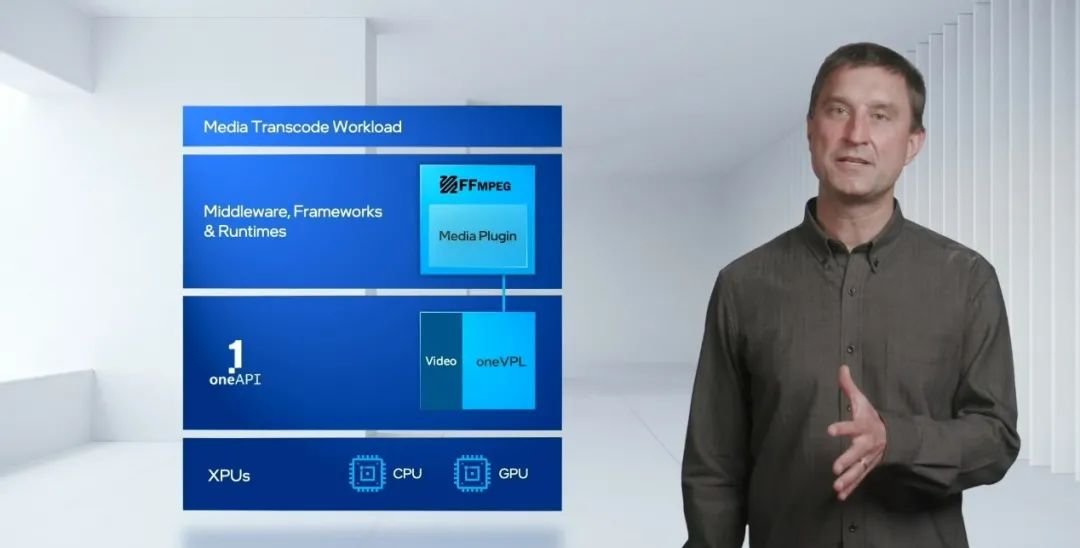
开发上,开发人员可利用目前Media SDK中的通用API,这一API也将于
明年迁移到oneAPI视频处理库
(oneVPL)
当中。
架构上,不仅是本次推出的新品,整个Xe产线都将全线优化Linux上的开发。通过intel给出的intelServer GPU的Android云游戏架构上,这款面向数据中心的独立GPU在Linux OS
(CentOS/Ubuntu)
的容器和虚拟化上提供了更好的优化,扩展代码库在Linux上的支持。从架构上来看,游戏流服务将输入到intel Cloud Rendering
(ICR)
中;利用FFMPEG编译、3DMesa渲染输出声音;利用intel GPU UMD渲染视频;而Android 游戏的云端主机和Android容器将利用intel桥接技术连接。
据悉,目前intel正与诸多软件和服务合作伙伴合作,共同将intel服务器GPU推向市场,其中包括
Gamestream、腾讯和Ubitus。
腾讯云游戏副总经理方亮表示:“intel是我们安卓云游戏解决方案上非常重要的合作伙伴。intel至强可扩展处理器和intel服务器GPU,打造了一个
高密度、低时延、低功耗、低TCO
(总拥有成本)
的解决方案,让我们能够在每台双卡服务器上生成超过100个游戏实例,诸如《王者荣耀》、《传说对决》。”
笔者认为,
此款云服务独立GPU在功耗上优化的非常彻底,
不仅使用了独立显卡Xe架构中最为低功耗的Xe-LP,还利用LPDDR4作为显存进一步降低功耗。众所周知数据中心是耗电和发热大户,因此只有在提高密度和性能的架构下降低器件的功耗才能全面压低功耗。
另一方面,操作系统和软件正逐渐靠拢开源,开源也是造就流量增长的功臣之一。正因为瞄准的主要是Android的游戏和视频市场,因此在爆发式增长的流量下,
无需扩充服务器,直接插独立GPU卡对于节约成本具有非凡的意义。
软件和硬件谁更重要?任何时候的答案都是“我都要”,特别是对电子工程师来说,软件硬件两手都要硬,产品亦如此,新发布的独立GPU亦如此。
讲起intel,oneAPI就是这家企业的一切的硬件的载体,也是intel不折不扣的“军师”。事实上,oneAPI早在“SuperComputing 2019”时就已放出测试版。经过无数的测试和功能完善,
直到今天oneAPI Gold正式发布,并将于今年12月正式交付。
名为Gold的oneAPI实际上也是oneAPI的1.0的版本,这款软件正是intel连接CPU、GPU、FPGA和其他加速器的“钥匙”,是实现XPU必不可少的一环。就如intel的战略“水利万物而不争”一样,
oneAPI包容着一切的硬件。
软件千千万,oneAPI到底有什么不一样?如果让笔者首推,一定是其直接编程的优秀开发体验,intel称之为DPC++
(Data ParallelC++)
,用一个等式简单解释就是
DPC++ =ISO C++ and Khronos SYCL。
正因为语法接近CUDA,所以在学习曲线上oneAPI是极简的,上手难度很低。
另一方面,intel的统一、简化架构编程模型,开发者可以借助oneAPI针对要解决的特定问题选择最佳加速器结构,且无需为此重写代码。intel对此的愿景是能够
提供毫不妥协的性能,不受限于单一厂商专用的代码构建,就能实现原有代码的集成。
在深度学习加速
(intel DL Boost)
方面,不仅支持PyTorch、mxnet、sklearn、NumPy、XGBoost,
最近也获得了微软Azure和TensorFlow的支持;众多领先的研究机构、公司和大学也支持oneAPI。
在工具方面,无论是应对数据中心、IoT还是
最新发布的独立显卡的渲染上,
oneAPI都得心应手。
发布会上,intel表示
oneAPI Gold工具包将于12月在本地和intelDevCloud上免费提供,
同时还将提供包含intel技术咨询工程师全球支持的商业版本。intel还会将intel Parallel Studio XE和intel System Studio工具套件迁移到oneAPI产品中。
另外,intel隐式SPMD程序编译器
(ISPC)
将在oneAPI级别零之上运行。oneAPI级别零是为XPU提供硬件抽象层的API的集合,由intel创建,提供了底层的直接到硬件的接口,以供客户跨多种硬件平台进行编程。ISPC是oneAPI渲染工具包的已安装基础语言,该工具包支持大多数主流的视频工作室基于至强处理器的渲染场,并将支持基于Xe架构的GPU。
笔者认为,
oneAPI Gold相比测试版已可以胜任XPU的艰巨任务,
从工具的迁移和GPU使用的渲染工具箱的加入,使得独立GPU加入至强可扩展处理器架构中无需使用其他软件。另一方面,oneAPI也是与硬件是相辅相成的,软硬件的闭环系统成为intel坚不可摧的生态。
左手一个硬件,右手一个软件
intel的XPU宏图
intel早前就已强调,现在intel是忠于数据,围绕数据业务和客户痛点而前行的一家公司。如果说intel的“护城河”是 “六大技术支柱”
(封装&制程,架构、内存&存储、互连、安全、软件)
,那么“城池”便是XPU+oneAPI的超异构计算。
晶体管耦合设计转向晶体管弹性设计、围绕CPU到围绕XPU、半导体硬件到半导体软硬件,
我们既是历史的见证者也是创造者。笔者曾多次强调,
一整套的产品都放在同一软硬件架构下,无论从性能上来讲,还是从稳定性、适配性、更替性上来说,均具天生优势。
在数据中心的XPU选择上,intel的不同级别定位产品,使得搭配更加丰富。从CPU上来说,intel的至强
(XEON)
可扩展处理器,命名上也采用了更加符合主流、直观易懂的“铜牌”、“银牌”、“金牌”、“铂金”的分级。
从FPGA上来讲,拥有最高密度、高性能的Stratix,高性能、低功耗的Agilex,中端主流的Arria,低功耗、成本敏感的Cyclone,低成本、单芯片的MAX。
从独立GPU上来讲,intel仍然拥有这样的定位,更加贴合不同应用的需求。
●
Xe-LP(低功耗):
定位为PC和移动平台最高效架构,主要使用LPDDR再次进行功耗的压缩。目前已在8月发布Xe DG1,近期发布了第11代intel酷睿移动处理器集成的锐炬®Xe显卡和intel锐炬®Xe MAX独立显卡。
● Xe-HP:定位为数据中心级、机架级媒体性能架构,能够提供GPU可扩展性和AI优化,Xe HP将于明年推出。涵盖了从一个区块(tile)到两个和四个区块的动态范围的计算,其功能类似于多核GPU。
● Xe-HPG:定位为专用于游戏优化的微架构,技术参数上,添加了GDDR6的新内存子系统提高性价比,支持光线追踪。是利用Xe-HP的扩展性,结合了Xe-LP的微架构变体。Xe-HPG预计将于2021年开始发货。
从路线上来看,intel的独立GPU远不止Xe-LP这种低功耗产品,将会从入门级显卡扩展到高性能计算,而实施这种策略的核心是所有系列产品能够实施同一套代码库。

包容这一切的毋庸置疑就是oneAPI,通过CPU+GPU+加速器+FPGA,便是标量+矢量+矩阵+空间的全方位计算。
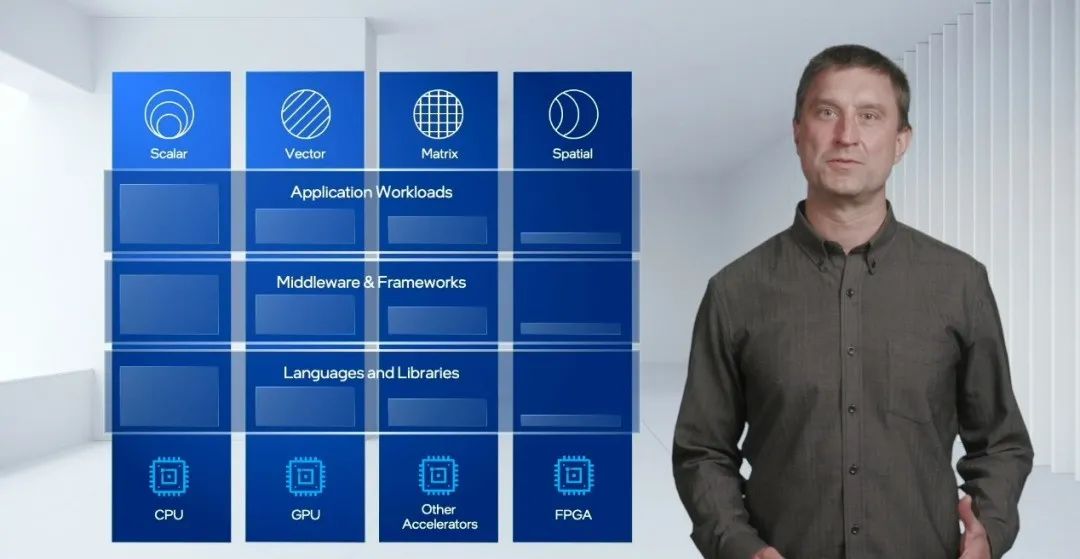
在摩尔定律日渐放缓的如今,其实摩尔所书写的未来还没有结束,XPU+oneAPI就将是最好的见证。
【1】初学不识“电容”意,看完这篇,电容高手非你莫属!
【2】必看!100个示波器基础知识问答
【3】
超全面!layout与PCB的29个基本关系
【1】终于整理齐了,电子工程师“设计锦囊”,你值得拥有!
【2】半导体行业的人都在关注这几个公众号
【3】
电子工程师自我“修炼宝典” 21ic独家整理!
免责声明:本文内容由21ic获得授权后发布,版权归原作者所有,本平台仅提供信息存储服务。文章仅代表作者个人观点,不代表本平台立场,如有问题,请联系我们,谢谢!








